Hello! As I said in the previous post I will be posting in this blog about my experiences in GSoC 2020 (if you do not know about it, see my first post).
Community bonding period has ended and officially the coding period begins now. This is my second (and late) post and I will talk about one of my main objectives in this project, text annotation, but first a little introduction:
In a supervised learning stage, data annotation is indispensable to machine learning models, so it can learn to recognize predetermined patterns and the algorithm can treat new, non-annotated data and successfully do its task. marK is a machine learning dataset annotation tool that aims to facilitate the important process of annotating data.
Text annotation
Text annotation, one type of data annotation, is the task of labeling text-based data. The acquired metadata make possible to train the learning model to recognize patterns to tackle a huge set of problems and niches. It has a bunch of fields, each one meant to a specific niche/objective, such as:
Phrase chunking

Phrase chunking consists of labelling parts of the text according to their grammatical meaning such as noun, verb, adjective, adverb and prepositional phrase, abbreviated as NP, VP, ADJP, ADVP and PP, respectively.
Named entity recognition

Named entity recognition (NER) represents a named entity in the text, these entities are labelled with predetermined labels such as corporation, localization, person, etc. Used to discern and recognize selected entities in a text.
Named entity linking
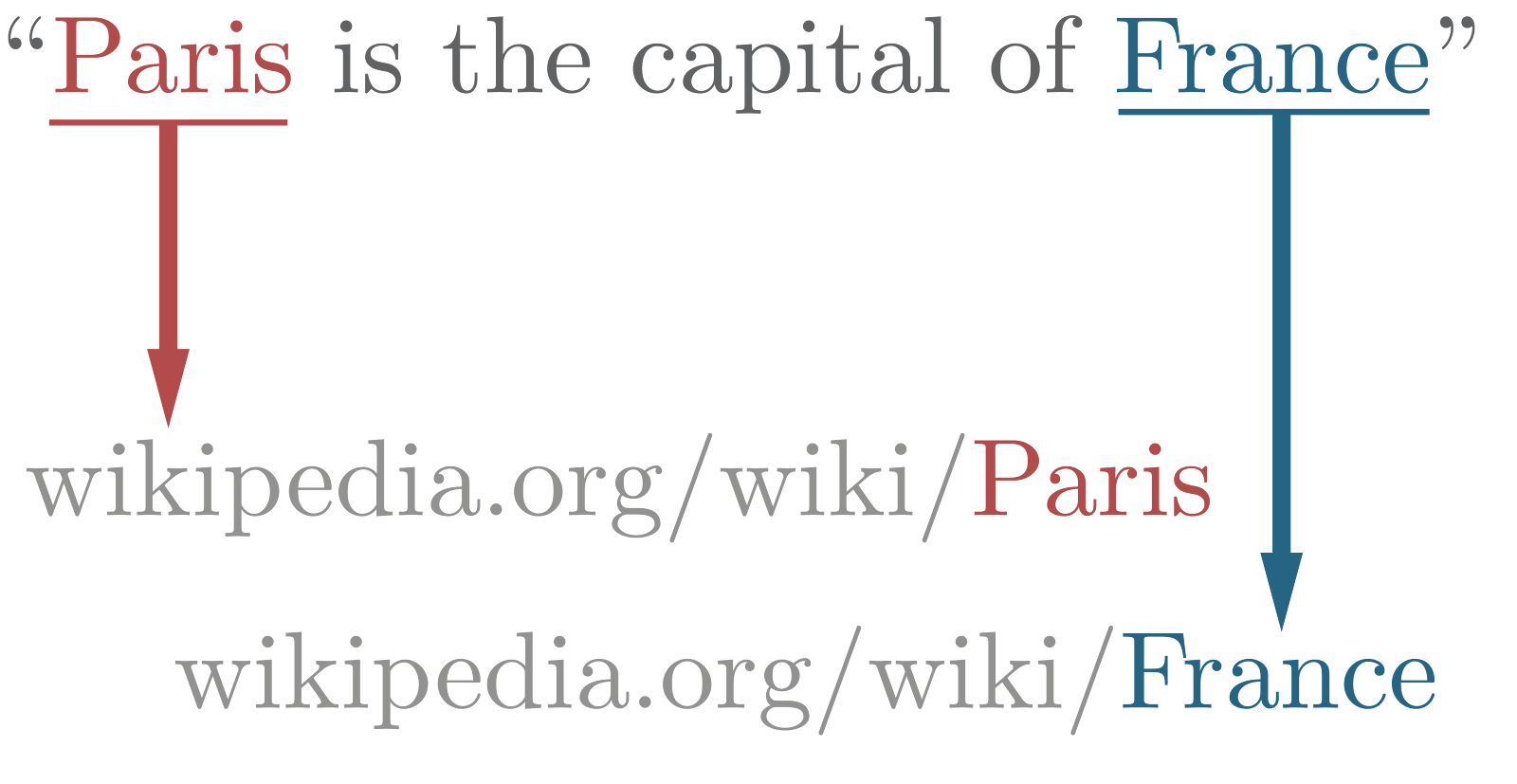
Named entity linking (NEL) is used along side with named entity recognition, its task is to link entity mentions to a corresponding entity in a external knowledge database such as Wikipedia.
By no means this was an exhaustive list, it is meant to list some possibilities of text annotation.
How text annotation should be like in marK
As of how the graphical interface should become I am still not sure, while I studied tools of text annotation for machine learning I perceived that it has a lot of potential to be better than I previously thought. Text annotation in marK should be as flexible as possible allowing the user to annotate easily and comfortably, for this I will talk with my mentor Caio and figure it out what could be the most reasonable way of doing it.
Behind the GUI, marK will have a whole subset of classes that will that care of tasks related to text annotation, having a bridge to the API KTextEditor that will play a big role in this part, being the one responsible for displaying the text and allowing its selection. marK also is going to have classes that will represent the metadata acquired in the annotation, holding the information and afterwards it will be used to generate the output (currently a JSON or XML file).
With this I hope that I have clarified and explained a little better about one of my main goals in this project.
That is it, see you in the next post 😉

Um comentário em “Google Summer of Code 2020 – Community bonding a bit about text annotation”